
INTRODUCTION
Cancer, one of the leading non-communicable causes of death worldwide, is a complex heterogeneous disease involving genomic alterations. Many studies have revealed the remarkable diagnostic and/or therapeutic value of identifying genomic alterations in cancer. For example, analysis of the BRCA1 and BRCA2 genes has been used to predict the risk of hereditary breast and ovarian cancer [1], and identification of BCR-ABL fusions and EGFR mutations inform the use of tyrosine-kinase inhibitors in the treatment of chronic myelogenous leukemia [2] and lung cancer [3], respectively. In addition, owing to the genomic heterogeneity of cancers, patients with histologically similar tumors may harbor different mutations, while patients with histologically distinct tumors may harbor similar mutations [4]. Therefore, the identification of genomic alterations is a critical step in personalized cancer care.
Traditionally, conventional techniques like Sanger sequencing, pyrosequencing, and fluorescence in situ hybridization have been used to identify genomic alterations in tumors. Nevertheless, the continually increasing number of clinically relevant genomic alterations has created an urgent need for higher throughput sequencing [5]. With the advent of next-generation sequencing (NGS) technologies, this issue is being addressed. Besides reducing sample quantity requirements, NGS sequencing is time-saving and cost-effective compared to traditional techniques. Furthermore, NGS technologies can detect low frequency mutations, and mutations scattered across larger genomic regions than can be analyzed using conventional molecular methods [6]. Owing to their unprecedented advantages and excellent performance in practice, NGS technologies are beginning to replace traditional molecular genetic techniques. These include Sanger sequencing, which has been the dominant approach and the gold standard for mutation detection for the past 30 years.
In the clinical laboratory, NGS approaches are generally used as diagnostic tools to provide genetic characterizations that inform the choice of a more precise medical treatment [7, 8]. In umbrella trials, NGS techniques are valuable for identifying individual genomic profiles and clustering the patients for targeted therapies. According to the Molecular Analysis for Therapy Choice (MATCH) Program conducted by the U.S. National Cancer Institute, the choice of a therapeutic agent is based on the specific molecular findings obtained using targeted NGS analysis rather than on the type of cancer [9]. However, the implementation of NGS in clinical laboratories still poses specific challenges and external quality assessment (EQA) programs are required to evaluate the results of NGS analyses from these labs. Recently, the U.S. Centers for Disease Control and Prevention (CDC), the American College of Medical Genetics and Genomics (ACMG), the Association for Molecular Pathology (AMP), and the College of American Pathologists (CAP) have defined guidelines for effective validation of NGS methods, for monitoring the analytical process, and for reporting variants [10–13]. The Next Generation Sequencing—Standardization of Clinical Testing (Nex-StoCT) Workgroup has described strategies regarding EQA for NGS testing in clinical laboratories. This group recommended use of sample types, including DNA from well-characterized cell lines, to evaluate analytic steps, except for DNA extraction. Unless derived from a tumor, most cell lines will not contain cancer specific variants. Variants present will be in high allelic ratios. CAP has initiated the development of an EQA for a methods-based NGS proficiency-testing product. Compared with analyte-based EQAs, methods-based EQAs mainly focus on evaluating specific steps rather than the entire testing system. The European Molecular Genetics Quality Network and the UK National External Quality Assessment Scheme for molecular genetics have launched a pilot methods-based EQA for NGS in Europe, but the results have not yet been published [14]. Irrespective of the strategy adopted for an EQA, serious attention should be paid to the results of NGS analyses produced by clinical laboratories.
A number of companies and clinical laboratories have recently embraced the NGS approach as a routine diagnostic method in China, and accordingly an EQA of non-invasive prenatal testing using NGS was implemented by the National Center for Clinical Laboratories (NCCL) of China. Our EQA revealed that performance varied among the participating labs [15]. Next generation sequencing was also one of the methods adopted by the participants in another EQA study by our group, wherein their detection of EML4-ALK fusions was evaluated [16]. To assess the proficiency of these laboratories in detecting different types of aberrations in cancer-related genes, the NCCL launched a nationwide pilot EQA in 2015 that examined their performance in detecting somatic mutations using NGS technologies. Here, we report the results of this EQA and evaluate the abilities of various laboratories to correctly identify single nucleotide variants (SNV) and small insertions and deletions (indels).
RESULTS
Validation of cancer-related genes panel
All the SNVs and indels included in the DNA samples were correctly detected by Beijing GenePlus using a NextSeq CN500 sequencer. However, the detection results obtained by Thermo Fisher Scientific using an Ion PGM System included only some of the expected variants due to its reportable range of target variants. The allele frequency detection reported by each group was within the acceptable range (see Materials and Methods). The allele frequencies of KRAS c.34G>T (p.Gly12Cys) and IDH2 c.419G>A (p.Arg140Gln) were between 1 % and 5 % in the samples that included them, and the allele frequencies of all other variant-alleles within samples were greater than 10 %. No false-negatives or false-positives were reported by either group. Allowing for their detectable ranges, the two laboratories successfully sequenced our panel of DNA samples and detected the included mutations in cancer-related genes using different dominant NGS platforms. The results of the validation of our panel of DNA samples are summarized in Table 1.
Table 1: The intended results and validation results of the EQA panel
Panel distribution and response
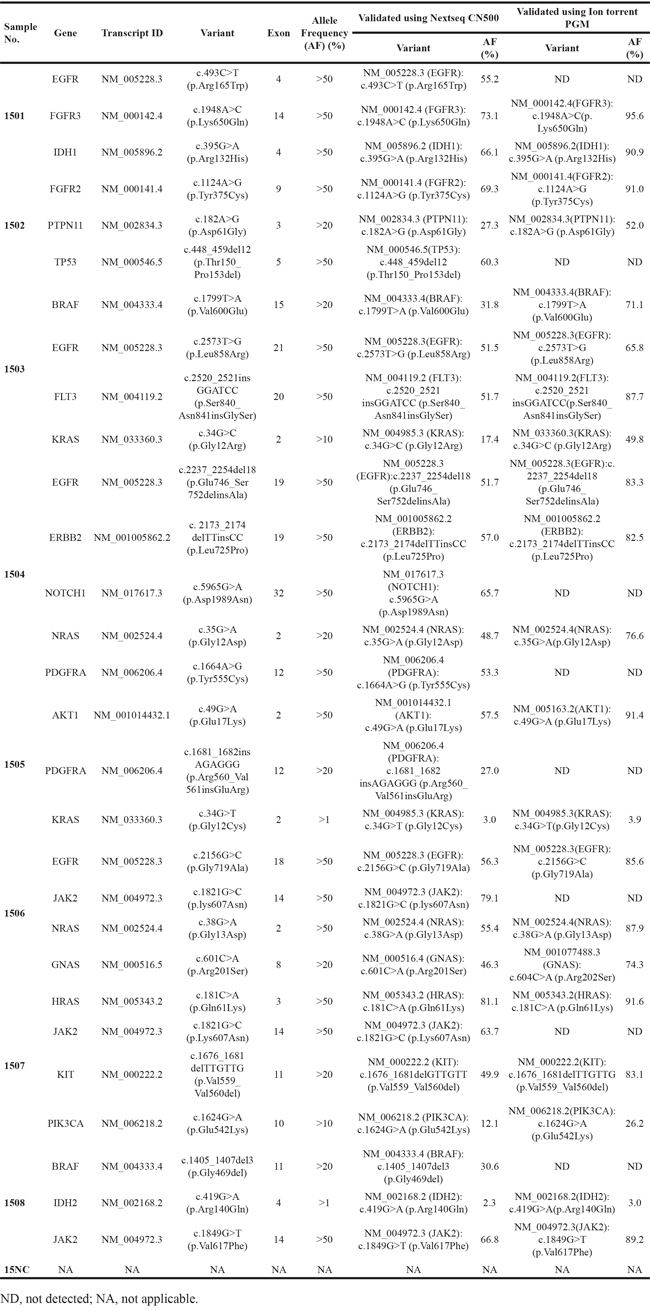
Seventy-five reports were received from 109 clinical laboratories before the cutoff date. Among these responses, ten laboratories did not report their detectable ranges which were necessary for analyzing our samples, and one commercial laboratory returned an incomplete dataset. Consequently, datasets from 64 laboratories, including 31 hospital or clinical laboratories and 33 commercial laboratories, were analyzed in this study. The panel was tested by participants using different next-generation sequencing approaches. The most commonly used platform was the Ion PGM System (Thermo Fisher Scientific Inc., Waltham, Massachusetts, USA) (27/64, 42.2 %), followed by the NextSeq CN500 (Hangzhou Berry Genomics, Hangzhou, China) (9/64, 14.1 %), the MiSeq (Illumina Inc., San Diego, California, USA) (6/64, 9.4 %), the HiSeq 2500 (Illumina) (6/64, 9.4 %), the Ion Proton System (Thermo Fisher Scientific Inc) (5/64, 7.8 %), the NextSeq 500 (Illumina) (4/64, 6.3 %), the HiSeq 3000 (Illumina) (3/64, 4.7 %), the DA8600 (Daan, Guangzhou, China) (3/64, 4.7 %), and the BioelectronSeq 4000 (CapitalBio, Beijing, China) (1/64, 1.6 %). Notably, 22 of 31 clinical/hospital labs (71.0 %) utilized Ion PGM/Proton instruments while 19 of 33 commercial labs (57.6 %) used Illumina platforms. Target enrichment was done using hybrid capture in 26 of the laboratories, whereas the remaining 38 laboratories employed the multiplex PCR method. All laboratories declared that the reported results had met their internal quality control standards. Figure 1 shows overviews of the various platforms and target enrichment methods used by the participating laboratories.
Figure 1: The distributions of laboratories based on differing characteristics. The distributions of laboratories using specific sequencing platforms and enrichment methods are shown in A. and B., respectively. The distributions of laboratories with different results of false-negatives and different results of false-positives are shown in C. and D., respectively. The distribution of different types of unexpected results is shown in E. NFN, number of false-negatives; NFP, number of false-positives.
NGS testing performance
The results submitted by the participants were compared with the expected reference results, and the overall performances of the laboratories were evaluated. The results were judged to be either acceptable or improvable based on the scoring system (see Materials and Methods). Twelve results different from the expected variant descriptions in ClinVar were reported and deemed to be correct because of their availability in the dbSNP database (Figure 2).
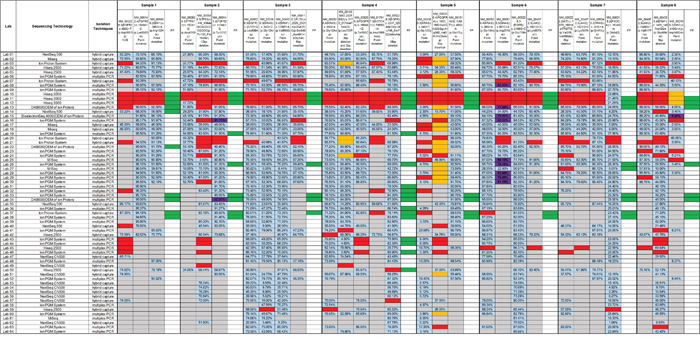
Figure 2: The performances of the 64 participating laboratories. The distributions of results are indicated by the columns of samples between the darkest vertical lines. Within each column, the components of variants contained in the sample and the false-positives detected by the participants are shown. An open box indicates no response from the laboratory; a blue box indicates a concordant result; an orange box means a slightly discordant response; a red box indicates a false-negative result; a green box indicates a false-positive result; a purple box indicates a correct variant having different description; and a grey box indicates no response was required because a variant fell outside the specific detectable range. The allele frequencies reported are shown inside the boxes. VUS, variant of uncertain significance; FP, false-positive.
The performances of 51.6% of laboratories (33/64) were found to be acceptable, and 26.6 % of these laboratories (17/64) correctly identified all the mutations within our panel of DNA samples. The results reported by the remaining 48.4% of the participants (31/64) were classified as improvable based on our criteria. Statistically, there was no significant difference between the performance of hospital/clinical labs as a group and the commercial labs as a group (p = 0.079). The performances of all 64 laboratories are summarized in Figure 2. The detection rates and the distributions of allele frequencies reported for each variant are shown in Figure 3.
Figure 3: The detection rate and distribution of allele frequencies for each variant in the sample panel. The detection rate of each variant identified in each sample is shown in A., and B. describes the distribution of allele frequencies for each variant. All the variants were identified with a median frequency over 10 %, except KRAS c.34G>T (p.Gly12Cys) and IDH2 c.419G>A (p.Arg140Gln) which were detected with frequencies around 3 % in samples 1505 and 1508, respectively.
In total, 449 mistakes were reported, including 201 false-negatives (201/449, 44.8 %) and 222 false-positives (222/449, 49.4 %) (Table 2) and 26 slightly discordant results (26/449, 5.8 %) (Table 3). It was noteworthy that 77.1 % of the false-negatives (155/201) came from only 12 laboratories and 93.7 % of the false-positives (208/222) came from only 9 participating labs, and the false-negatives or false-positives were reported in more than 5 samples by each lab involved. No false-negatives were found in the results from 45.3 % of the labs (29/64), and no false-positives were found in the results from 68.8 % of the labs (44/64). The distribution of false-negatives and false-positives reported by the participants is shown in Figure 1. Table 2 shows details regarding the false-positives. We observed that 10.8 % (24/222) of the false-positive results involving eight variants included in the designed panel were reported in the samples that did not contain them and 36.0 % (80/222) of the false-positive results involving 4 variants in NA12878 that were not included on the synthetic fragments were reported (Table 2). We also assessed the false-negative results of different combinations of target-enrichment strategies and sequencing platforms. Among labs using multiplex PCR as the enrichment method, 88 (88/159, 55.3%) false-negatives were reported by those which utilized Illumina platforms and 47 (47/587, 8.0 %) false-negatives were reported from labs adopting semiconductor sequencing systems. Among labs using hybrid capture strategies, 14 (14/383, 3.7 %) false-negatives came from laboratories using Illumina platforms and 52 (52/116, 44.8 %) false-negatives were reported by those adopting semiconductor sequencing systems.
Table 2: The results of false-positives
Gene |
Transcript ID |
Variant |
No. of |
Sample No. |
Variant in NA12878 (Y/N) |
Included in EQA panel (Y/N) |
|---|---|---|---|---|---|---|
FGFR2 |
NM_000141.2 |
c.1124A>G (p.Tyr375Cys) |
5 |
1501/1505/1506 |
N |
Y/1502 |
FLT3 |
NM_004119.2 |
c.2520_2521insGGATCC |
5 |
1501/1502/1504/ 1506/1507 |
N |
Y/1503 |
SMARCB1 |
NM_003073.2 |
c.1119-41G>A(p.?) |
1 |
All |
N |
N |
NM_003073.3 |
c.215C>A (p.Thr72Lys) |
1 |
1501 |
N |
N |
|
STK11 |
NM_000455 |
c.1062C>G (p.Phe354Leu) |
1 |
All |
N |
N |
NM_000455.4 |
c.1086C>T (p.Tyr362Tyr) |
1 |
1506 |
N |
N |
|
NM_000455.4 |
c.1085A>T (p.Tyr362Phe) |
1 |
1505 |
N |
N |
|
ATM |
NM_000051.3 |
c.3912A>G (p.(=)) |
1 |
1501/1505/1506/ 1507/1508 |
N |
N |
FGFR3 |
NM_001163213.1 |
c.1936A>G (p.Asn646Asp) |
1 |
1501/1505 |
N |
N |
NM_000142.4 |
c.1953G>A (p.(=)) |
2 |
All |
Y |
N |
|
NM_001163213.1 |
c.1959G>A (p.Thr653Thr) |
1 |
All |
N |
N |
|
IDH1 |
NM_005896.3 |
c.353C>T (p.Pro118Leu) |
1 |
1501/1505/ 1506/1508 |
N |
N |
NM_005896.2 |
c.394_395CG>GT (p.Arg132Val) |
2 |
1502/1504/1508 |
N |
N |
|
RB1 |
NM_000321.2 |
c.2009T>C (p.Leu670Pro) |
1 |
1501/1505/1508 |
N |
N |
SMAD4 |
NM_005359.5 |
c.767A>T (p.Gln256Leu) |
2 |
1501/1504/1505/ 1506/1507/1508 |
N |
N |
TP53 |
NM_000546.5 |
c.215C>G (p.Pro72Arg) |
4 |
All |
Y |
N |
NM_000546 |
c.460G>T (p.Gly154Cys) |
2 |
1505/1506 |
N |
N |
|
NM_000546.5 |
c.455C>G (p.Pro152Arg) |
1 |
1502 |
N |
N |
|
NM_000546 |
c.474C>T (p.Arg158=) |
3 |
1502 |
N |
N |
|
NM_000546.5 |
c.453C>G (p.Pro151=) |
1 |
1502 |
N |
N |
|
NM_000546.5 |
c.797G>T (p.Gly266Val) |
1 |
All |
N |
N |
|
NM_000546 |
c.458C>T (p.Pro153Leu) |
3 |
1502 |
N |
N |
|
EGFR |
NM_005228.3 |
c.2361G>A (p.(=)) |
3 |
All |
Y |
N |
NM_005228.3 |
c.837_838delGAinsCG (p.Asn280Asp) |
1 |
1501/1502/1503/ 1507/1508 |
N |
N |
|
NM_005228.3 |
c.2236_2254delGAATTAAGAGAAGCAACAT (p.Glu746fs) |
2 |
1504 |
N |
N |
|
NM_004985.3 |
c.2573T>G (p.Leu858Arg) |
1 |
1504 |
N |
Y/1503 |
|
NM_005228 |
c.2156G>C (p.Gly719Ala) |
1 |
1505 |
N |
Y/1506 |
|
NM_005228.3 |
c.2237_2254del18 (p.Glu746_Ser752delinsAla) |
1 |
1505 |
N |
Y/1504 |
|
ERBB2 |
NM_004448.3 |
c.3508C>G (p.Pro1170Ala) |
1 |
All |
Y |
N |
NM_004448.3 |
c.2580A>G (p.(=)) |
1 |
1501/1504/1505/ 1506/1507/1508 |
N |
N |
|
NM_004448.3 |
c.2263_2264delTTinsCC (p.Leu755Pro) |
1 |
1505 |
N |
Y/1504 |
|
NM_004448.3 |
c.1558T>A (p.Cys520Ser) |
1 |
1505 |
N |
N |
|
NPM1 |
NM_002520.5 |
NM_002520.6:() |
1 |
1502/1503/ 1507/1508 |
-* |
N |
KRAS |
NM_004985 |
c.33_34insGGAGCT (p.Ala11_Gly12insGlyAla) |
3 |
1503/1505 |
N |
N |
NM_033360.3 |
c.148A>C (p.Thr50Pro) |
1 |
1505 |
N |
N |
|
BRAF |
NM_004333.4 |
c.1799T>A (p.Val600Glu) |
1 |
1504 |
N |
Y/1503 |
GNAS |
NM_080425.3 |
c.2530C>T (p.Arg844Cys) |
1 |
1505 |
N |
N |
ALK |
NM_004304.4 |
c.3551G>A (p.Gly1184Glu) |
1 |
1505/1508 |
N |
N |
NM_004304.4 |
c.3627A>G (p.Arg1209Arg) |
1 |
1508 |
N |
N |
|
NOTCH1 |
NM_017617.3 |
c.4802A>T (p.His1601Leu) |
1 |
1505 |
N |
N |
NRAS |
NM_002524.4 |
c.35G>A (p.Gly12Asp) |
2 |
1505/1506 |
N |
Y/1504 |
NM_002524.4 |
c.359T>G (p.Leu120Trp) |
1 |
1508 |
N |
N |
|
NM_002524 |
c.38G>C (p.Gly13Ala) |
1 |
1505 |
N |
N |
|
GNAQ |
NM_002072.4 |
c.671C>A (p.Thr224Asn) |
1 |
1507 |
N |
N |
KIT |
NM_000222.2 |
c.1676T>G (p.Val559Gly) |
2 |
1507 |
N |
N |
NM_001093772 |
c.1663_1668del6 (p.555_556delValVal) |
1 |
1507 |
N |
N |
|
PTPN11 |
NM_002834.3 |
c.1514T>C (p.Val505Ala) |
1 |
1507 |
N |
N |
* variant not identified.
Table 3: Overview of 26 slightly discordant results
Gene |
Sample No. |
Transcript ID |
Intended Variant |
Lab |
Variant Reported |
|---|---|---|---|---|---|
ERBB2 |
4 |
NM_001005862.2 |
c.2173_2174delTTinsCC (p.Leu725Pro) |
03 |
c.2174T>C(p.L725S) |
20 |
c.2174T>C(p.L725S) |
||||
21 |
c.2174T>C(p.L725S) |
||||
24 |
c.2174T>C(p.Leu725Ser) |
||||
PDGFRA |
5 |
NM_006206.4 |
c.1681_1682insAGAGGG (p.Arg560_Val561insGluArg) |
02 |
c.1676_1677insGAGGGA (p.Trp559delinsTrpArgGlu) |
03 |
c.1676_1677insGAGGGA (p.Trp559delinsTrpArgGlu) |
||||
06 |
c.1676_1677insGAGGGA (p.Trp559_Arg560insArgGlu) |
||||
07 |
c.1676_1677insGAGGGA (p.W559delinsWRE) |
||||
08 |
c.1676_1677insGAGGGA (p.Trp559_Arg560insArgGlu) |
||||
13 |
c.1676_1677insGAGGGA (p.Trp559_Arg560insArgGlu) |
||||
15 |
c.1676_1677insGAGGGA (p. Trp559_Trp560ArgGlu) |
||||
17 |
c.1676_1677insGAGGGA (p.Trp559delinsTrpArgGlu) |
||||
18 |
c.1676_1677insGAGGGA (p.Trp559delinsTrpArgGlu) |
||||
21 |
c.1676_1677insGAGGGA (p.W559delinsWRE) |
||||
22 |
c.1676_1677insGAGGGA (p.Trp559_Arg560insArgGlu) |
||||
23 |
c.1676_1677insGAGGGA (p.Trp559delinsTrpArgGlu) |
||||
26 |
c.1676_1677insGAGGGA (p.Trp559_Arg560insArgGlu) |
||||
27 |
c.1676_1677insGAGGGA (p.W559_R560insRE) |
||||
28 |
c.1676_1677insGAGGGA (p.Trp559_Arg560insArgGlu) |
||||
29 |
c.1676_1677insGAGGGA (p.Trp559_Arg560insArgGlu) |
||||
30 |
c.1676_1677insGAGGGA (p.Trp559_Arg560insArgGlu) |
||||
51 |
c.1676_1677insGAGGGA (p.Trp559delinsTrpArgGlu) |
||||
60 |
c.1676_1677insGAGGGA (p.Trp559delinsTrpArgGlu) |
||||
IDH2 |
8 |
NM_002168.2 |
c.419G>A(p.Arg140Gln) |
10 |
c.419G>T(p.R140L) |
11 |
c.419G>T(p.R140L) |
||||
12 |
c.419G>T(p.R140L) |
DISCUSSION
Sequencing large and complex DNA samples, such as those generated in transcriptome sequencing or whole-genome sequencing experiments, is expensive and time consuming. Targeted genome sequencing is a more efficient and affordable method that focuses on higher coverage or read depth over limited regions of specific genes. Targeted sequencing of cancer related genes has been the prominent approach used by clinical laboratories for routine screening of genomic variations in cancer-patient samples [17]. However, an EQA system for targeted genome sequencing by NGS has been not available until now. The ideal EQA samples should be obtained from clinical specimens that have been tested in a clinical laboratory, and should allow all phases of the testing process to be evaluated [18, 19]. However, NGS laboratories usually analyze tumor DNA and normal DNA in parallel to find somatic alteration present in the tumor. Thus, for formalin-fixed paraffin-embedded (FFPE) treated tumor tissues, normal tissues or mononuclear cells from the same patients need to be provided simultaneously as EQA control samples. Therefore, use of FFPE clinical tissue samples for large-scale EQA studies would be nearly impossible because of the limited number of tumor and normal tissue samples available from a given patient. In addition, although FFPE tissue samples are the most commonly used samples for routine diagnostics, the fixation process usually yields degraded DNA, and sequence artifacts are frequently detected due to DNA deamination [20–26]. In light of these issues, synthetic DNA samples containing specific sequences have been used for EQA studies [18], and artificially constructed DNA samples containing clinically relevant mutations have been designed for similar performance evaluation [27, 28]. In this study, we generated a panel of DNA samples by mixing genomic DNA from a HapMap cell line with synthetic DNA fragments engineered to contain previously reported cancer-related mutations. The HapMap genomic DNA, NA12878, has been developed by the National Institute for Standards and Technology (NIST) as a certified reference material [29] and a high confidence variant call set covering 78% of the genome has been characterized [30], which makes the genetic background of the samples available. Our approach was less complicated and cumbersome than the previously reported strategy of performing site-directed mutagenesis, and many different mutations can be included in one sample by using synthetic DNA fragments [27]. We directly synthesized and purified DNA fragments of 300-500 bp harboring our desired mutations. These fragments are larger than the amplicons or sheared DNA fragments generated during the NGS library preparation process, and notably the DNA sequences flanking the mutations in these fragments are identical to the genomic DNA sequences that would flank them in vivo. In our panel, each DNA sample contained both wild-type alleles and the corresponding disease-associated artificial allelic variants. The results of our validation process showed that the abundance of most of the artificial allelic variants in our EQA samples were within the detection limits of all the participating laboratories. Therefore, our panel of DNA samples is a valid substitute for a panel of clinically extracted human genomic DNA samples, and is suitable for evaluating genomic variation screening in labs using NGS.
Overall, only 26.6 % (17/64) of the laboratories detected the artificially mutated alleles with no mistakes in this EQA study, and 48.4 % (31/64) of the participating labs did not produce acceptable results. This shows that the application of NGS in clinical laboratories around China is still problematic and requires improvement. To facilitate this, we analyzed the unsatisfactory results to identify causal factors within the different sample preparation and sequencing processes. The problems with the sequencing results included both excessive false-positives and excessive false-negatives.
Almost half of the incorrect results were false-positives, which are known to occur for various reasons. First, since the identification of barcodes within the sequencing reads is a critical step for ensuring that subsequent characterization of the individual samples is accurate [31], errors in identifying sequence-ligated barcodes during the de-multiplexing process will cause errors in the results. In the present study, eight of the variants that were included in some of our DNA samples were detected in samples that did not contain them, suggesting possible mistakes in DNA barcode identification (Table 2). Second, in theory, the control sample containing only extracted genomic DNA should act as a baseline reference without any of the artificial allelic variants. Hence, we believe that the results involving 4 variants in NA12878 should be unfiltered results, which could be attributed to errors during the sequencing and bioinformatics procedures. These errors typically include mononucleotide stretch errors in semiconductor sequencing platforms [32], substitution errors in Illumina instruments [33], or complete omission of the filtering step.
On the other hand, among the 201 false-negatives, 60 of the 92 incorrectly reported indels (65.2 %) came from labs utilizing the multiplex PCR method to generate multiplex amplicons in the process of library preparation. As the primers designed for multiplex PCR are crucial for this enrichment method, the failure in detection could be explained by mismatches between primers and their target DNA sequences. We also found that among the labs using multiplex PCR method, the false-negative rate using Ion Torrent platforms (8.0 %) was much lower than that using Illumina platforms (55.3 %). We speculate that the laboratories using Ion Torrent platforms always adopted ‘off the shelf’ panels offered by Thermo Fisher, which have been extensively validated and the information about mutation detection performance (e.g. the reportable range) can be obtained from the manufacturers directly. In contrast, among participants using the hybrid capture method, the false-negative rate when using Ion Torrent platforms (44.8 %) was greater than that when using the Illumina platforms (3.7 %). The reason might be that hybridization-based enrichment strategies require more bioinformatics supports than PCR-based ones [34]. More commercial software and free pipelines available for the Illumina sequencing platforms might be helpful for the labs to handle the data produced using hybrid-capture enrichment. These also presented that the validation of the NGS assays might be absent in some laboratories. Therefore, we recommend that the full validation of variant detection is indispensable for laboratories when NGS tests are developed.
Furthermore, many of the unexpected results, such as the 26 slightly discordant results, should be attributed to systemic errors. These include PCR errors during the library or template preparation process [35], GC contents bias [36, 37], and potential biases within the bioinformatics pipeline such as the signal-processing and base calling limitations of the software used [36]. Errors might also appear if the sequences of junction fragments were not aligned to NCBI build 37, which was assigned as the reference sequence in this EQA. The noticeably concentrated distribution of false-negatives and false-positives implies that errors might be caused by improper operations performed within specific labs. Therefore, good standardized operating procedures (SOPs) and well-trained staff are critical, given that mistakes can occur even with the most effective instruments if procedures are performed incorrectly.
In conclusion, we designed and conducted the first nationwide EQA of NGS-based targeted sequencing by laboratories in China. We used a mixture of synthetic and genomic DNA instead of clinical specimens as samples, and validated the suitability of our samples for use in an EQA. However, there are certain limitations to our approach. First, our samples were processed differently than the typical clinical samples usually received by these labs for routine diagnostics, in that preparation of our samples did not involve a gDNA extraction process. Hence, the evaluation regarding dealing with clinical samples in laboratory was not considered in this study. However, we provided high quality DNA for this EQA, and attention should be paid to describing the sequencing process rather than the procedure for DNA isolation within these labs. Second, although each mutation was located in a central position within a synthetic DNA fragment, the limited fragment sizes might prevent labs from using Sanger sequencing to confirm their results, because their primer binding sites may lay outside the regions of the genome included in our fragments. To shed further light on the capabilities of diagnostic labs, future EQA studies should use FFPE samples that consist of untransformed cells and cells from the same lineage that have been modified using the CRISPR/Cas9 system to harbor desired mutations. Future studies could also include more low-percentage variants to better evaluate the detection of low allele frequency mutations.
Our results imply an urgent requirement for improved laboratory training in the procedures of targeted NGS, likely due to the complexity of the process. Many guidelines and recommendations for standardizing NGS technologies have been produced [10-12, 38, 39], which were summarized in Figure 4. It is essential for laboratories to establish standard operating procedure (SOP), follow all quality control (QC) metrics at every step, and document the values in each test. Based on SOP and QC metrics, the NGS process should be validated to establish the expected performance characteristics within each lab. We also emphasize the importance of internal quality control (IQC) and EQA studies to verify the reliability of NGS results. As part of our EQA of labs performing targeted NGS, detailed analyses of the results were provided so that all participants became aware of the performance of various workflows and laboratories. We also provided the opportunity to retest samples for any participating labs that requested it. In the future, EQAs of targeted NGS within labs in China will be performed twice a year and the limitations of the test panel will be provided.
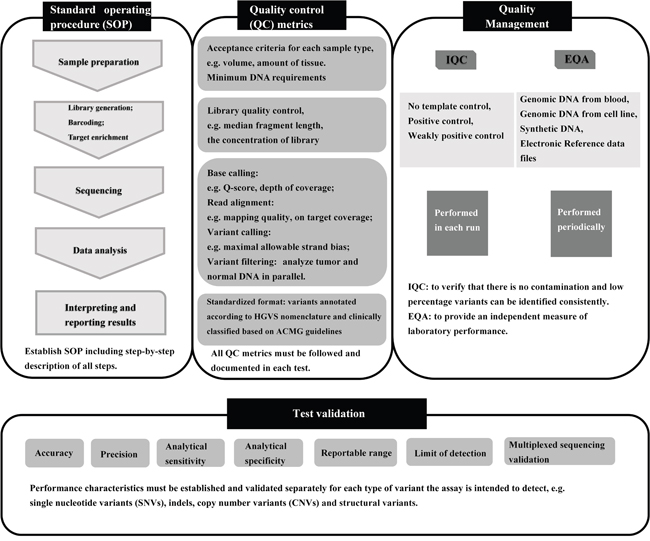
Figure 4: Overview of the targeted NGS workflow and quality assurance. IQC, internal quality control; EQA, external quality assessment.
MATERIALS AND METHODS
Composition and preparation of cancer-related genes panel
The panel of eight DNA samples included mutations to 20 cancer-related genes commonly detected by clinical laboratories. The panel was prepared by the NCCL (Beijing, China) using synthetic DNA fragments and genomic DNA. Firstly, genomic DNA was extracted from a lymphoblastoid cell line (GM12878) from the International HapMap Project, which was purchased from the Coriell Cell Repositories (Coriell, New Jersey, USA). DNA from GM12878 is the same as the reference material developed by NIST, and the genome of this sample has been well characterized and is publicly available [30]. The genomic DNA was quantified using a FLUOstar Omega plate reader (BMG LABTECH, Ortenberg, Germany). Secondly, based on data from public databases ClinVar (http://www.ncbi.nlm.nih.gov/clinvar/) and the National Comprehensive Cancer Network Clinical Practice Guidelines in Oncology (NCCN Guidelines, update 2015), one SNV of uncertain clinical significance in EGFR, and 28 clinically significant mutations including SNVs and indels within 20 cancer-related genes were selected as candidate variants. The target gene sequences containing these variants were designed according to the curated human genome resources in the NCBI reference sequence (RefSeq) database (NCBI build 37) (http://www.ncbi.nlm.nih.gov/RefSeq/) and the sequence dataset for the HapMap sample NA12878 in the GeT-RM Browser (http://www.ncbi.nlm.nih.gov/variation/tools/get-rm/). The sizes of the desired sequences were 300-500 base pairs (bp) and the expected mutations were located in the central portions of these fragments. Synthesis of the DNA fragments was performed by Sangon Biological Technology (Shanghai, China). Recombinant plasmids containing specific mutated gene fragments were constructed and the fragments were then obtained by cleavage with restriction enzymes. Each DNA fragment was quantified using the FLUOstar Omega plate reader (BMG LABTECH, Ortenberg, Germany). Lastly, the sequences of the different synthetic DNA fragments were confirmed by Sanger sequencing and the fragments were mixed with the genomic DNA extracted from the GM12878 cell line. Specifically, 3-5 mutated fragments were pooled with the genomic DNA in controlled proportions in each sample, and the total mass of the nucleic acid was at least 1 μg. Table 1 summarizes the composition of the panel of samples: eight of the samples included synthetic DNA fragments, while one sample included only genomic DNA and acted as a control to filter out irrelevant mutations. Samples were dispensed as 30 μL aliquots into 200 μL thin-wall polypropylene PCR tubes. Each of the PCR tubes was then each placed in a 1.5 mL siliconized glass vial, in case the contents of the PCR tubes spilled during transit. The vials were labeled “NCCL NGS EQA 2015” and were randomly assigned numbers from 1-8. The samples were stored at -20 °C before shipment to the laboratories.
Validation of cancer-related genes panel
The panel of cancer-related genes was evaluated by Beijing GenePlus Technology (Beijing, China) and by Thermo Fisher Scientific Inc. (Beijing, China) using the same processes used for their routine patient sample testing.
The Beijing GenePlus group used a NextSeq CN500 sequencer (Hangzhou Berry Genomics, Hangzhou, China). DNA samples received from NCCL were first fragmented using a Bioruptor® Pico sonication system (Diagenode Inc., Denville, New Jersey, USA) and quality control was performed using an Agilent 2100 Bioanalyzer (Agilent Technologies, Palo Alto, California, USA) to ensure an average fragment size of 200-300 bp. The subsequent steps included end repair, A-tailing, and ligation with a sequencing adapter containing a unique nucleic acid barcode using a Kapa Hyper Prep Kit (Kapa Biosystems, Wilmington, Massachusetts, USA). The libraries were quantified using an ABI 7500 Real-Time PCR System (Applied Biosystems, Foster City, California, USA), and 96 libraries with different tags were pooled and quantified. The pooled library was sequenced using the NextSeq 500 High Output Kit (300 cycles) (Illumina Inc., San Diego, California, USA).
The Thermo Fisher Scientific group used an Ion PGM System (Thermo Fisher Scientific Inc., Waltham, Massachusetts, USA). Quantification of DNA samples was performed using the Qubit dsDNA BR Assay Kit and Qubit 3.0 Fluorometer (Invitrogen, Thermo Fisher Scientific Inc., Waltham, Massachusetts, USA). The processes, including multiplex PCR enrichment and library preparation, were performed using the Biometra TProfessional Standard Gradient 96 Thermocycler (Biometra, Gottingen, Germany) according to the manufacturer’s instructions. The libraries were quantified using an ABI 7500 Real-Time PCR System (Applied Biosystems, Foster City, California, USA). Emulsion PCR was performed with the Ion PGM Template OT2 200 Kit using the Ion One Touch 2 system (Thermo Fisher Scientific Inc., Waltham, Massachusetts, USA). Ion sphere particles (ISP) were enriched using the E/S module and were then sequenced on the Ion PGM System using an Ion PGM™ Hi-Q™ Sequencing Kit (both from Thermo Fisher Scientific Inc., Waltham, Massachusetts, USA).
Participating labs and data analysis
The prepared samples were shipped to 109 clinical laboratories at room temperature. All the laboratories were assigned the same coded samples and were required to perform the detection using their routine procedures. Detailed instructions for storage conditions and assay procedures were provided. The sample 15NC was specially described as normal genomic DNA extracted from normal tissues or blood cells. Laboratories were required to submit their results, including the variants and corresponding allele frequencies, within four weeks of receiving the test panel. All variants were reported following the Human Genome Variation Society (HGVS) guidelines. Since a variant might have different descriptions across different transcripts, we recommended the participants to use the reference transcripts in ClinVar database. In addition, questionnaires were sent to obtain information regarding their detectable ranges, minimum detection limits, procedures (including the platforms and reagents used for generation of DNA libraries and sequencing), databases and bioinformatics tools employed, and assay-specific quality metrics such as minimum coverage thresholds, mapping qualities, and Q scores.
To assess participant performances effectively, a set of scoring rules were established previously. Results that differed from the expected (correct) results were considered either false-negatives or false-positives. Each false-negative resulted in a deduction of 10 points from the perfect score of 100 points, whereas each false-positive resulted in loss of 5 points. A discordant result with a sequence alteration that differed within 5 bp was classified as a slightly discordant result and caused a loss of only 2 points, while a discrepancy greater than 5 bp between the reported and actual sequences resulted in losing 5 points. The variants out of the specific detectable range were not considered in the scoring process. The performance was classified as either acceptable or improvable: For labs processing a panel containing 20 or more genes, scores of 80 or more points were regarded as acceptable, and scores of less than 80 points were considered to be improvable. For labs focusing on less than 20 genes, scores of 90 or more points were necessary for an acceptable performance rating, whereas scores of less than 90 points were considered improvable. The results obtained from the laboratories were analyzed based on their detection limits and their respective reportable ranges in addition to the expected results. All statistical analysis was performed with SPSS 16.0. Performances were compared using the Fisher’s exact test with a two-tailed statistical significance at p < 0.05.
ACKNOWLEDGMENTS
This work was supported by a grant from the Special Fund for Health Scientific Research in the Public Interest from National Population and Family Planning Commission of the People’s Republic of China (No. 201402018).
CONFLICTS OF INTEREST
The authors declare no conflict of interest.
REFERENCES
1. Feliubadaló L, Lopez-Doriga A, Castellsagué E, del Valle J, Menéndez M, Tornero E, Montes E, Cuesta R, Gómez C, Campos O, Pineda M, González S, Moreno V, et al. Next-generation sequencing meets genetic diagnostics: development of a comprehensive workflow for the analysis of BRCA1 and BRCA2 genes. Eur J Hum Genet. 2013; 21:864-70. doi: 10.1038/ejhg.2012.270
2. Druker BJ, Talpaz M, Resta DJ, Peng B, Buchdunger E, Ford JM, Lydon NB, Kantarjian H, Capdeville R, Ohno-Jones S, Sawyers CL. Efficacy and safety of a specific inhibitor of the BCR-ABL tyrosine kinase in chronic myeloid leukemia. N Engl J Med. 2001; 344:1031-7. doi: 10.1056/NEJM200104053441401
3. Rosell R, Moran T, Queralt C, Porta R, Cardenal F, Camps C, Majem M, Lopez-Vivanco G, Isla D, Provencio M, Insa A, Massuti B, Gonzalez-Larriba JL, et al. Screening for epidermal growth factor receptor mutations in lung cancer. N Engl J Med. 2009; 361:958-67. doi: 10.1056/NEJMoa0904554
4. Schweiger MR, Kerick M, Timmermann B, Isau M. The power of NGS technologies to delineate the genome organization in cancer: from mutations to structural variations and epigenetic alterations. Cancer Metastasis Rev. 2011; 30:199-210. doi: 10.1007/s10555-011-9278-z
5. Luthra R, Chen H, Roy-Chowdhuri S, Singh RR. Next-Generation Sequencing in Clinical Molecular Diagnostics of Cancer: Advantages and Challenges. Cancers. 2015; 7:2023-36. doi: 10.3390/cancers7040874
6. Ivanova M, Shivarov V, Pavlov I, Lilakos K, Naumova E. Clinical Evaluation of a Novel Nine-Gene Panel for Ion Torrent PGM Sequencing of Myeloid Malignancies. Mol Diagn Ther. 2016; 20:27-32. doi: 10.1007/s40291-015-0172-1
7. Gagan J, Van Allen EM. Next-generation sequencing to guide cancer therapy. Genome Med. 2015; 7:80. doi: 10.1186/s13073-015-0203-x
8. Roychowdhury S, Iyer MK, Robinson DR, Lonigro RJ, Wu YM, Cao X, Kalyana-Sundaram S, Sam L, Balbin OA, Quist MJ, Barrette T, Everett J, Siddiqui J, et al. Personalized oncology through integrative high-throughput sequencing: a pilot study. Sci Transl Med. 2011; 3:111ra121. doi: 10.1126/scitranslmed.3003161
9. Abrams J, Conley B, Mooney M, Zwiebel J, Chen A, Welch JJ, Takebe N, Malik S, McShane L, Korn E, Williams M, Staudt L, Doroshow J. National Cancer Institute's Precision Medicine Initiatives for the new National Clinical Trials Network. Am Soc Clin Oncol Educ Book. 2014:71-6. doi: 10.14694/EdBook_AM.2014.34.71
10. Rehm HL, Bale SJ, Bayrak-Toydemir P, Berg JS, Brown KK, Deignan JL, Friez MJ, Funke BH, Hegde MR, Lyon E, Working Group of the American College of Medical G and Genomics Laboratory Quality Assurance C. ACMG clinical laboratory standards for next-generation sequencing. Genet Med. 2013; 15:733-47. doi: 10.1038/gim.2013.92
11. Gargis AS, Kalman L, Berry MW, Bick DP, Dimmock DP, Hambuch T, Lu F, Lyon E, Voelkerding KV, Zehnbauer BA, Agarwala R, Bennett SF, Chen B, et al. Assuring the quality of next-generation sequencing in clinical laboratory practice. Nat Biotechnol. 2012; 30:1033-6. doi: 10.1038/nbt.2403
12. Aziz N, Zhao Q, Bry L, Driscoll DK, Funke B, Gibson JS, Grody WW, Hegde MR, Hoeltge GA, Leonard DG, Merker JD, Nagarajan R, Palicki LA, et al. College of American Pathologists' laboratory standards for next-generation sequencing clinical tests. Arch Pathol Lab Med. 2015; 139:481-93. doi: 10.5858/arpa.2014-0250-CP
13. Schrijver I, Aziz N, Farkas DH, Furtado M, Gonzalez AF, Greiner TC, Grody WW, Hambuch T, Kalman L, Kant JA, Klein RD, Leonard DG, Lubin IM, et al. Opportunities and challenges associated with clinical diagnostic genome sequencing: a report of the Association for Molecular Pathology. J Mol Diagn. 2012; 14:525-40. doi: 10.1016/j.jmoldx.2012.04.006
14. Schrijver I, Aziz N, Jennings LJ, Richards CS, Voelkerding KV, Weck KE. Methods-based proficiency testing in molecular genetic pathology. J Mol Diagn. 2014; 16:283-7. doi: 10.1016/j.jmoldx.2014.02.002
15. Zhang R, Zhang H, Li Y, Han Y, Xie J, Li J. External Quality Assessment for Detection of Fetal Trisomy 21, 18, and 13 by Massively Parallel Sequencing in Clinical Laboratories. J Mol Diagn. 2016; 18:244-52. doi: 10.1016/j.jmoldx.2015.10.003
16. Li Y, Zhang R, Peng R, Ding J, Han Y, Wang G, Zhang K, Lin G, Li J. Reliability Assurance of Detection of EML4-ALK Rearrangement in Non-Small Cell Lung Cancer: The Results of Proficiency Testing in China. J Thorac Oncol. 2016; 11:924-9. doi: 10.1016/j.jtho.2016.03.004.
17. Ballester LY, Luthra R, Kanagal-Shamanna R, Singh RR. Advances in clinical next-generation sequencing: target enrichment and sequencing technologies. Expert Rev Mol Diagn. 2016; 16:357-72. doi: 10.1586/14737159.2016.1133298
18. Kalman LV, Lubin IM, Barker S, du Sart D, Elles R, Grody WW, Pazzagli M, Richards S, Schrijver I, Zehnbauer B. Current landscape and new paradigms of proficiency testing and external quality assessment for molecular genetics. Arch Pathol Lab Med. 2013; 137:983-8. doi: 10.5858/arpa.2012-0311-RA
19. Bellissimo DB and American College of Medical Genetics. Practice guidelines and proficiency testing for molecular assays. Transfusion. 2007; 47:79S-84S. doi: 10.1111/j.1537-2995.2007.01316.x
20. Spencer DH, Sehn JK, Abel HJ, Watson MA, Pfeifer JD, Duncavage EJ. Comparison of clinical targeted next-generation sequence data from formalin-fixed and fresh-frozen tissue specimens. J Mol Diagn. 2013; 15:623-33. doi: 10.1016/j.jmoldx.2013.05.004
21. Williams C, Ponten F, Moberg C, Soderkvist P, Uhlen M, Ponten J, Sitbon G, Lundeberg J. A high frequency of sequence alterations is due to formalin fixation of archival specimens. Am J Pathol. 1999; 155:1467-71. doi: http://dx.doi.org/10.1016/S0002-9440(10)65461-2
22. Dijkstra JR, Tops BB, Nagtegaal ID, van Krieken JH, Ligtenberg MJ. The homogeneous mutation status of a 22 gene panel justifies the use of serial sections of colorectal cancer tissue for external quality assessment. Virchows Arch. 2015; 467:273-8. doi: 10.1007/s00428-015-1789-5
23. Quach N, Goodman MF, Shibata D. In vitro mutation artifacts after formalin fixation and error prone translesion synthesis during PCR. BMC Clin Pathol. 2004; 4:1. doi: 10.1186/1472-6890-4-1
24. Do H, Dobrovic A. Sequence artifacts in DNA from formalin-fixed tissues: causes and strategies for minimization. Clin Chem. 2015; 61:64-71. doi: 10.1373/clinchem.2014.223040
25. Kerick M, Isau M, Timmermann B, Sultmann H, Herwig R, Krobitsch S, Schaefer G, Verdorfer I, Bartsch G, Klocker H, Lehrach H, Schweiger MR. Targeted high throughput sequencing in clinical cancer settings: formaldehyde fixed-paraffin embedded (FFPE) tumor tissues, input amount and tumor heterogeneity. BMC Med Genomics. 2011; 4:68. doi: 10.1186/1755-8794-4-68
26. Wong SQ, Li J, Salemi R, Sheppard KE, Do H, Tothill RW, McArthur GA, Dobrovic A. Targeted-capture massively-parallel sequencing enables robust detection of clinically informative mutations from formalin-fixed tumours. Sci Rep. 2013; 3:3494. doi: 10.1038/srep03494
27. Jarvis M, Iyer RK, Williams LO, Noll WW, Thomas K, Telatar M, Grody WW. A novel method for creating artificial mutant samples for performance evaluation and quality control in clinical molecular genetics. J Mol Diagn. 2005; 7:247-51. doi:10.1016/S1525-1578(10)60551-X
28. Wang T, Wei JJ, Sabatini DM, Lander ES. Genetic screens in human cells using the CRISPR-Cas9 system. Science. 2014; 343:80-84. doi: 10.1126/science.1246981
29. National Institute of Standards and Technology. RM 8398 - Human DNA for Whole-Genome Variant Assessment. Available online: https://www-s.nist.gov/srmors/view_detail.cfm?srm=8398 (accessed on 18 July 18, 2016).
30. Zook JM, Chapman B, Wang J, Mittelman D, Hofmann O, Hide W, Salit M. Integrating human sequence data sets provides a resource of benchmark SNP and indel genotype calls. Nat Biotechnol. 2014; 32:246-251. doi: 10.1038/nbt.2835
31. Kong Y. Btrim: a fast, lightweight adapter and quality trimming program for next-generation sequencing technologies. Genomics. 2011; 98:152-3. doi: 10.1016/j.ygeno.2011.05.009
32. Liu L, Li Y, Li S, Hu N, He Y, Pong R, Lin D, Lu L, Law M. Comparison of next-generation sequencing systems. J Biomed Biotechnol. 2012; 2012:251364. doi: 10.1155/2012/251364
33. Minoche AE, Dohm JC, Himmelbauer H. Evaluation of genomic high-throughput sequencing data generated on Illumina HiSeq and genome analyzer systems. Genome Biol. 2011; 12:R112. doi: 10.1186/gb-2011-12-11-r112
34. Kozarewa I, Armisen J, Gardner AF, Slatko BE, Hendrickson CL. Overview of Target Enrichment Strategies. Curr Protoc Mol Biol. 2015; 112:7.21.1-23. doi: 10.1002/0471142727.mb0721s112.
35. Quail MA, Smith M, Coupland P, Otto TD, Harris SR, Connor TR, Bertoni A, Swerdlow HP, Gu Y. A tale of three next generation sequencing platforms: comparison of Ion Torrent, Pacific Biosciences and Illumina MiSeq sequencers. BMC genomics. 2012; 13:341. doi: 10.1186/1471-2164-13-341
36. Ross MG, Russ C, Costello M, Hollinger A, Lennon NJ, Hegarty R, Nusbaum C, Jaffe DB. Characterizing and measuring bias in sequence data. Genome Biol. 2013; 14:R51. doi: 10.1186/gb-2013-14-5-r51
37. Bragg LM, Stone G, Butler MK, Hugenholtz P, Tyson GW. Shining a light on dark sequencing: characterising errors in Ion Torrent PGM data. PLoS Comput Biol. 2013; 9:e1003031. doi: 10.1371/journal.pcbi.1003031
38. Clinical and Laboratory Standards Institute. Nucleic Acid Sequencing Methods in Diagnostic Laboratory Medicine; Approved Guideline-Second Edition. CLSI document MM09-A2. Wayne: Clinical and Laboratory Standards Institute. 2014.
39. New York State Department of Health. “Next Generation” Sequencing (NGS) guidelines for somatic genetic variant detection. Available online: http://www.wadsworth.org/sites/default/files/WebDoc/1300145166/NextGenSeq_ONCO_Guidelines.pdf (accessed on 19 May 2014).